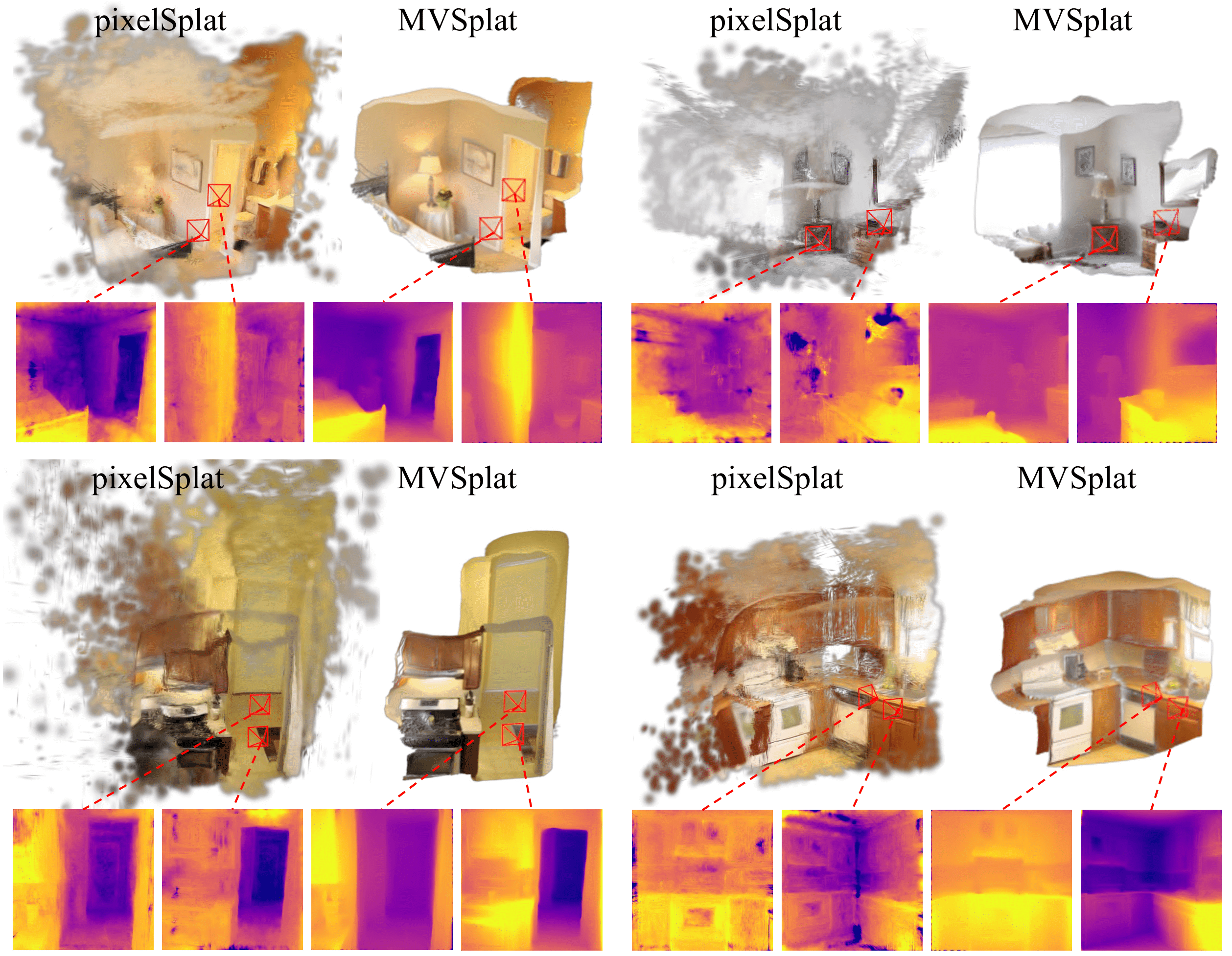
We present qualitative comparisons with the following state-of-the-art models:

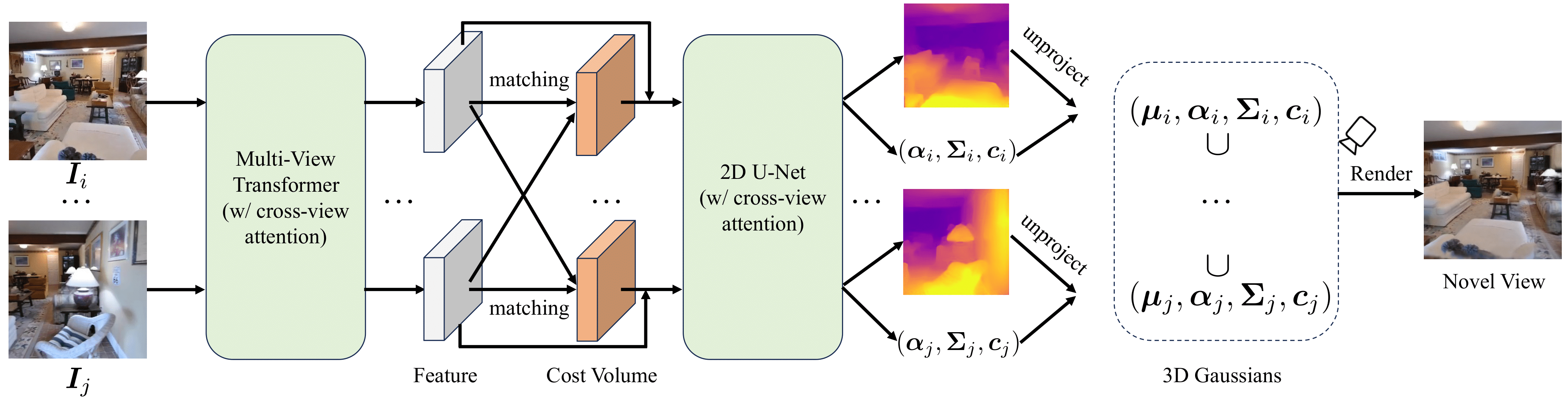
Our MVSplat produces significantly higher-quality 3D Gaussian primitives than the latest state-of-the-art pixelSplat. The readers are invited to view the corresponding ".ply" files of the 3D Gaussians exported from both models provided at HERE. We recommend viewing them with online viewers, e.g., 3D Gaussian Splatting with Three.js (camera up should be set to "0,0,1").
Our MVSplat is inherently superior in generalizing to out-of-distribution novel scenes, primarily due to the fact that the cost volume captures the relative similarity between features, which remains invariant compared to the absolute scale of features. Here, we present cross-dataset generalization by training models solely on RealEstate10K (indoor scenes), and directly test them on DTU (object-centric scenes) and ACID (outdoor scenes).

@article{chen2024mvsplat,
title = {MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images},
author = {Chen, Yuedong and Xu, Haofei and Zheng, Chuanxia and Zhuang, Bohan and Pollefeys, Marc and Geiger, Andreas and Cham, Tat-Jen and Cai, Jianfei},
journal = {arXiv preprint arXiv:2403.14627},
year = {2024},
}