Abstract
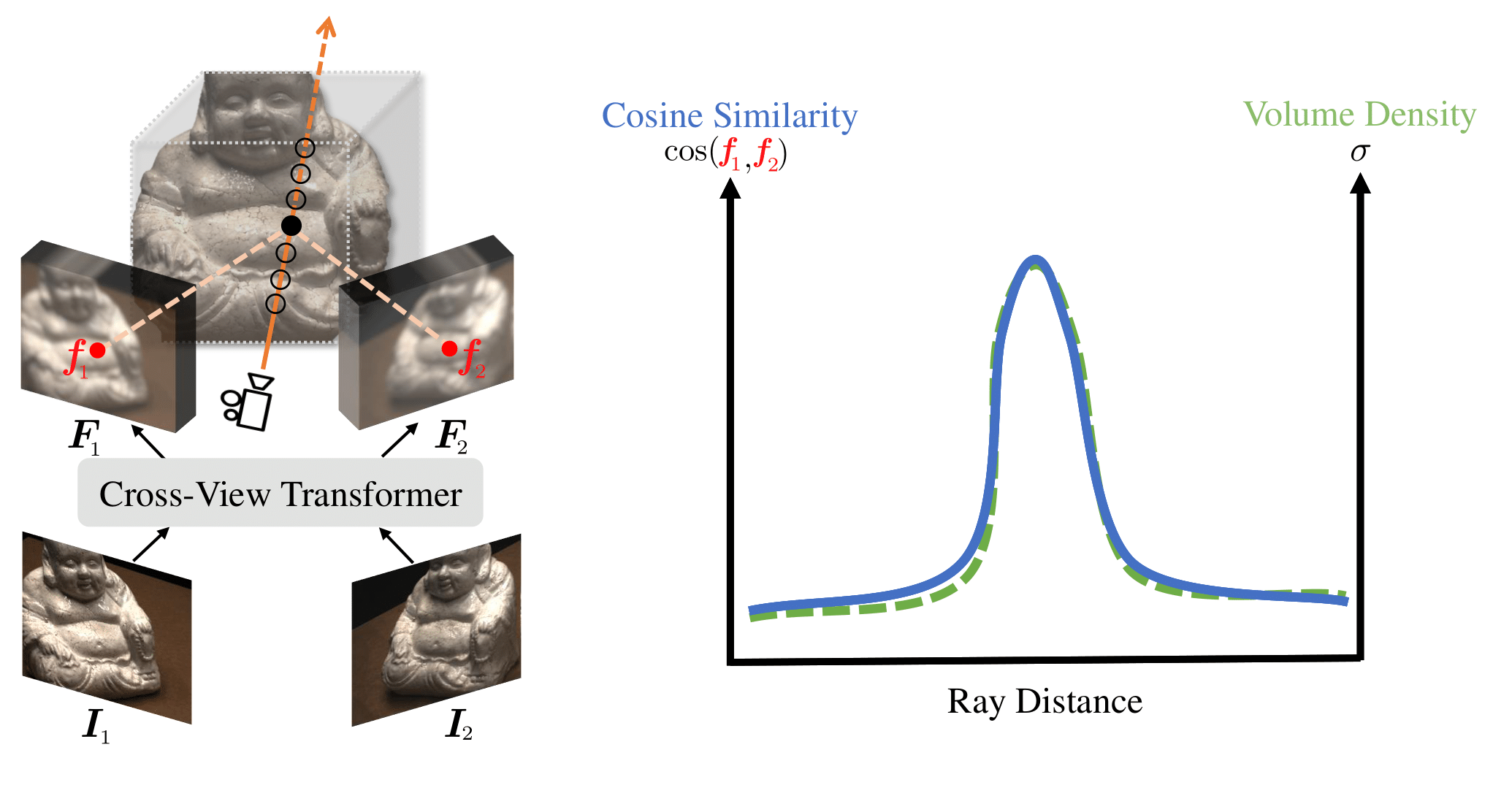
We present a new generalizable NeRF method that is able to directly generalize to new unseen scenarios and perform novel view synthesis with as few as two source views. The key to our approach lies in the explicitly modeled correspondence matching information, so as to provide the geometry prior to the prediction of NeRF color and density for volume rendering. The explicit correspondence matching is quantified with the cosine similarity between image features sampled at the 2D projections of a 3D point on different views, which is able to provide reliable cues about the surface geometry. Unlike previous methods where image features are extracted independently for each view, we consider modeling the cross-view interactions via Transformer cross-attention, which greatly improves the feature matching quality. Our method achieves state-of-the-art results on different evaluation settings, with the experiments showing a strong correlation between our learned cosine feature similarity and volume density, demonstrating the effectiveness and superiority of our proposed method.
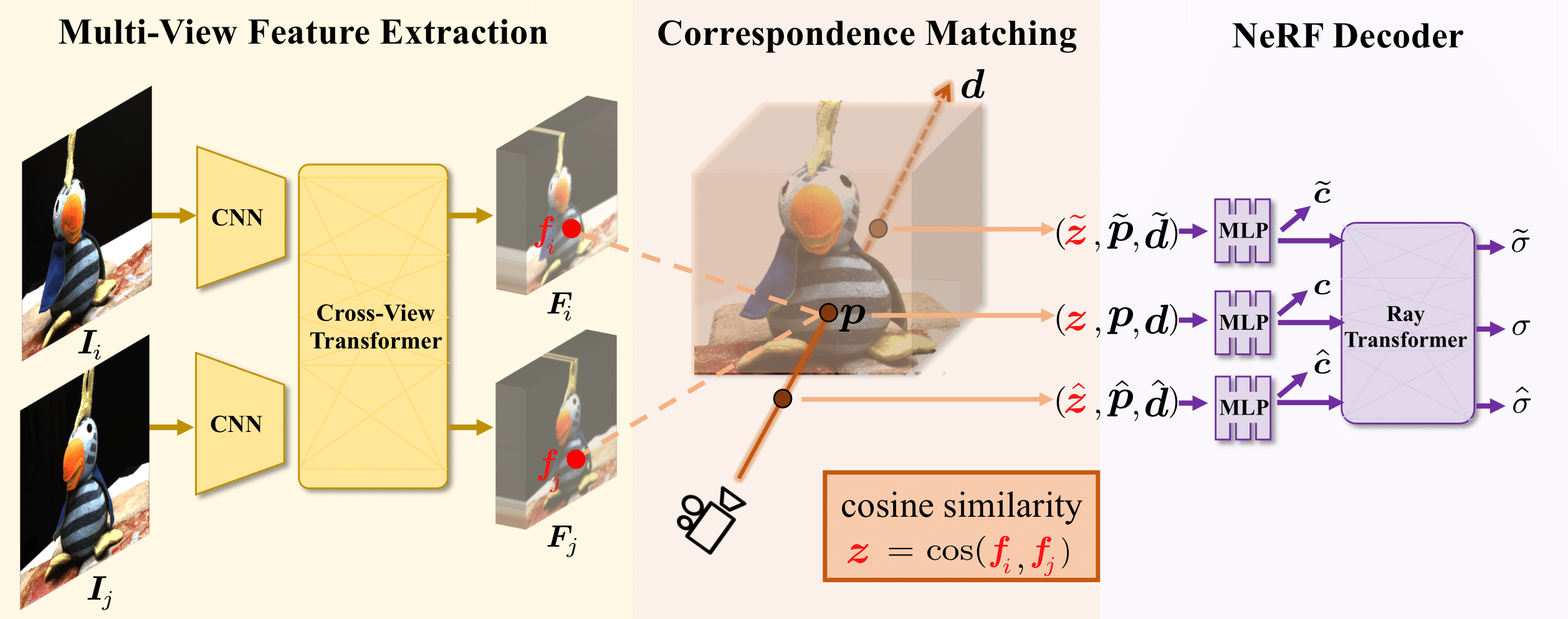
Model Architecture
Direct Inference on In-the-Wild Unseen Scenes






Direct Inference on Benchmark Test Scenes



Quantitative Comparisons

Acknowledgements
BibTeX
@article{chen2025explicit,
title={Explicit correspondence matching for generalizable neural radiance fields},
author={Chen, Yuedong and Xu, Haofei and Wu, Qianyi and Zheng, Chuanxia and Cham, Tat-Jen and Cai, Jianfei},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2025},
publisher={IEEE}
}